
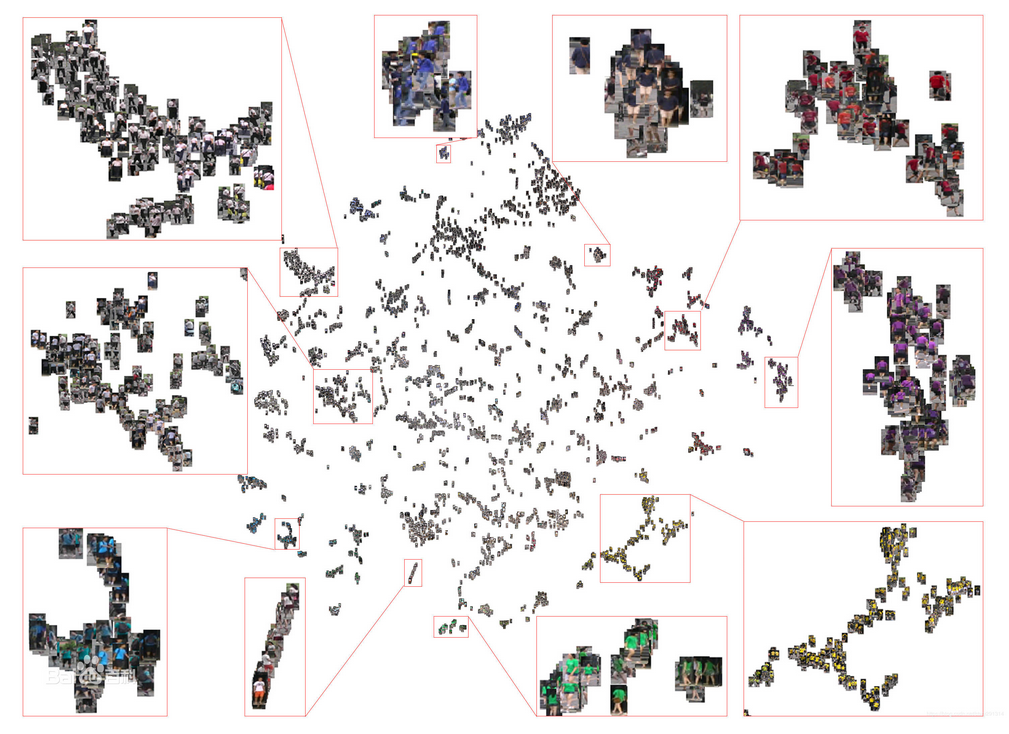
行人重识别是什么?
行人重识别(Person re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补目前固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合,可广泛应用于智能视频监控、智能安保等领域。由于不同摄像设备之间的差异,同时行人兼具刚性和柔性的特性 ,外观易受穿着、尺度、遮挡、姿态和视角等影响,使得行人重识别成为计算机视觉领域中一个既具有研究价值同时又极具挑战性的热门课题。
技术难点
能不能用人脸识别做重识别?
理论上是可以的。但是有两个原因导致人脸识别较难应用:首先,广泛存在后脑勺和侧脸的情况,做正脸的人脸识别难。其次,摄像头拍摄的像素可能不高,尤其是远景摄像头里面人脸截出来很可能都没有32x32的像素。所以人脸识别在实际的重识别应用中很可能有限。有些人靠衣服的颜色就可以判断出来了,还需要行人重识别么?
衣服颜色确实是行人重识别做出判断一个重要因素,但光靠颜色是不足的。首先,摄像头之间是有色差,并且会有光照的影响。其次,有撞衫(颜色相似)的人怎么办,要找细节,但比如颜色直方图这种统计的特征就把细节给忽略了。在多个数据集上的测试表明,光用颜色特征是难以达到50%的top1正确率的。总结:
- 不同下摄像头造成行人外观的巨大变化;
- 目标遮挡(Occlusion)导致部分特征丢失;
- 不同的 View,Illumination 导致同一目标的特征差异;
- 不同目标衣服颜色近似、特征近似导致区分度下降;
基本方法
基于部件匹配的方法
** 基于人体在三维空间中的结构(结构信息),人体图像可以进行分割,按部件来执行匹配。**
- 常见方案是水平切割,就是将图像切为几个水平的条。由于人体身材往往差不多,所以可以用简单的水平条来做一一比较。
- 在领域中做匹配,采用的是一个正方形的邻域。
- 另一个较新的方案是先在人体上检测部件(手,腿,躯干等等)再进行匹配,这样的话可以减少位置的误差,但可能引入检测部件的误差。
- 类似LSTM的attention匹配,但必须pair输入,测试时间较长,不适合快速图像检索。
- 如图,类似人脸对齐,使用STN 将行人整个图像先利用热度图对齐,再匹配。

基于损失函数的方法
基于高层语义信息,设置一些辅助任务,帮助模型学习到好的特征表达。
- 身份损失(Identification loss)直接拿身份label做多类分类。
- 鉴定损失(Verification loss)比较两个输入图像是否为同一人。
- 身份损失(Identification loss)+鉴定损失(Verification loss),将以上两种损失函数混合。
- 三样本损失 (Triplet loss) 以3个样本为一组,同一人的图像特征距离应小于不同人。
- 加入属性任务 (attribute)比如判断是否背包,是男生还是女生等等。人们遇见陌生人也是利用这些属性来描述。
- 数据增强 混合多数据集训练 ,加入训练集上 生成对抗网络(GAN)生成的数据,如图:

识别机制
如图
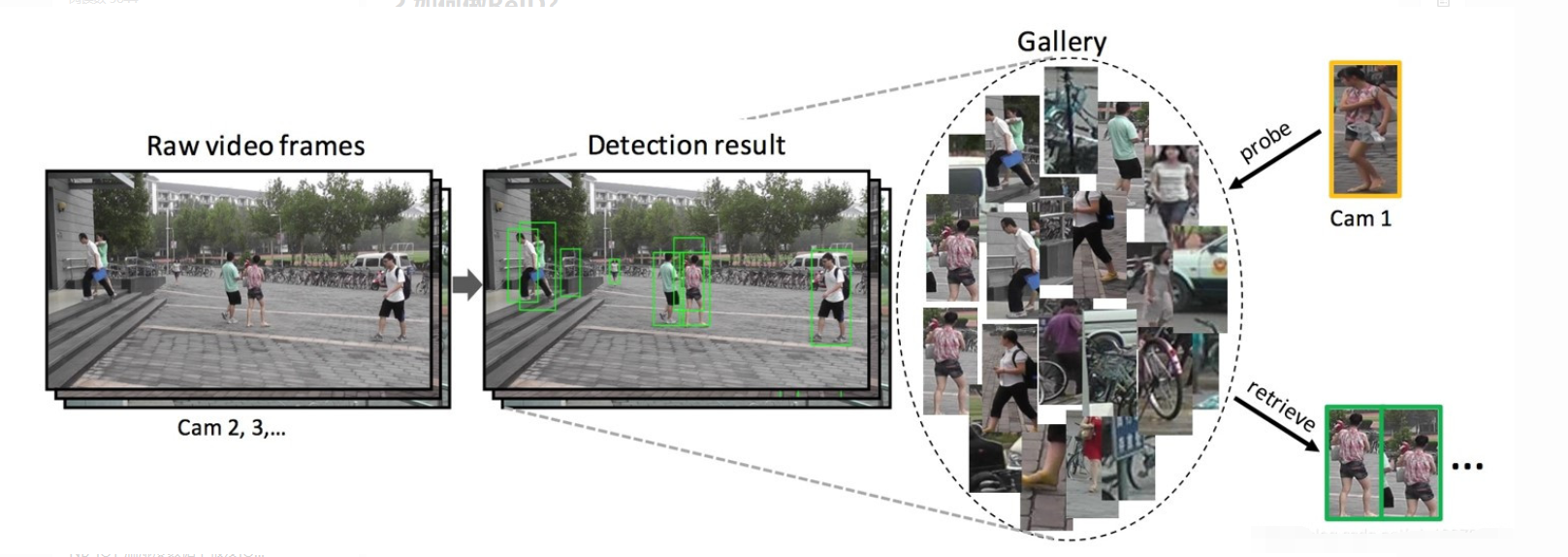
首先要做的是Detection,也就是检测出行人,其实这一步数据集已经帮我们做到了,下面介绍数据集的时候会讲到不同数据集采用的不同的目标检测方法以及ID的标注方式。剩下的部分,就是要去训练一个特征提取网络,根据特征所计算的度量距离得到损失值,我们选用一个优化器去迭代找到loss最小值,并不断更新网络的参数达到学习的效果。在测试的时候,我们用将要检索的图片(称为query或者probe),在底库gallery中,根据计算出的特征距离进行排序,选出最TOP的几张图片,来达到目标检索的目的。
下面两张图分别是训练阶段和测试阶段的示意图:
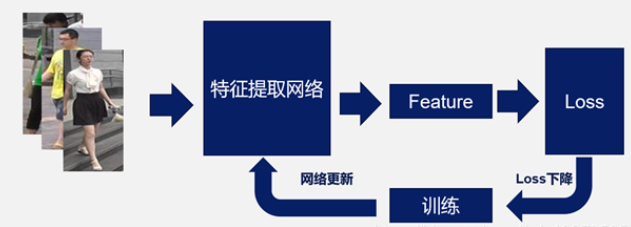
** 训练阶段**
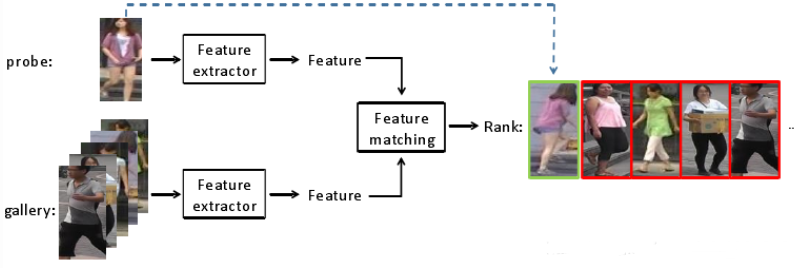
评测指标
rank-k
算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中
举个例子:
假如在人脸识别中,底库中有100个人,现在来了1个待识别的人脸(假如label为m1),与底库中的人脸比对后将底库中的人脸按照得分从高到低进行排序,我们发现:
如果识别结果是m1、m2、m3、m4、m5……,则此时rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
如果识别结果是m2、m1、m3、m4、m5……,则此时rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
如果识别结果是m2、m3、m4、m5、m1……,则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%;
同理,当待识别的人脸集合有很多时,则采取取平均值的做法。例如待识别人脸有3个(假如label为m1,m2,m3),同样对每一个人脸都有一个从高到低的得分,
比如:
人脸1结果为m1、m2、m3、m4、m5……,
人脸2结果为m2、m1、m3、m4、m5……,
人脸3结果m3、m1、m2、m4、m5……,
则此时rank-1的正确率为(1+1+1)/3=100%;
rank-2的正确率也为(1+1+1)/3=100%;
rank-5的正确率也为(1+1+1)/3=100%;
比如:
人脸1结果为m4、m2、m3、m5、m6……,
人脸2结果为m1、m2、m3、m4、m5……,
人脸3结果m3、m1、m2、m4、m5……,
则此时rank-1的正确率为(0+0+1)/3=33.33%;
rank-2的正确率为(0+1+1)/3=66.66%;
rank-5的正确率也为(0+1+1)/3=66.66%;
mAP(mean average precision)
反应检索的人在数据库中所有正确的图片排在排序列表前面的程度,能更加全面的衡量ReID算法的性能。如下图,假设该检索行人在gallery中有10张图片,在检索的list中位置(rank)分别为1、2、3、4、5、6、7、8、9,则ap为(1/ 1 + 2 / 2 + 3 / 3 + 4 / 4 + 5 / 5 + 6 / 6 + 7 / 7 + 8 / 8 + 9 / 9) / 10 = 0.90;ap较大时,该行人的检索结果都相对靠前,对所有query的ap取平均值得到mAP
