
JMM
内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 作用:
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 规定了线程和内存之间的一些关系
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成
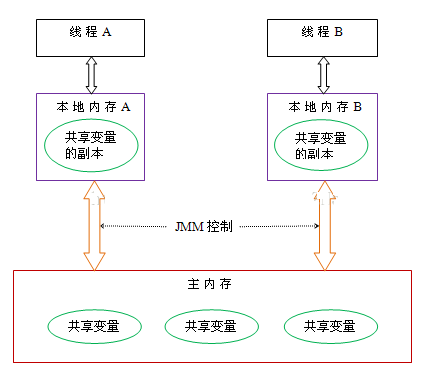
主内存和工作内存:
- 主内存:计算机的内存,也就是经常提到的 8G 内存,16G 内存,存储所有共享变量的值
- 工作内存:存储该线程使用到的共享变量在主内存的的值的副本拷贝
CPU处理速度非常快,相对CPU来说,去主内存获取数据这个事情太慢了,CPU就提供了L1,L2,L3的三级缓存,每次去主内存拿完数据后,就会存储到CPU的三级缓存,每次去三级缓存拿数据,效率肯定会提升。
这就带来了问题,现在CPU都是多核,每个线程的工作内存(CPU三级缓存)都是独立的,会告知每个线程中做修改时,只改自己的工作内存,没有及时的同步到主内存,导致数据不一致问题。

JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
内存交互
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作,每个操作都是原子的
非原子协定:没有被 volatile 修饰的 long、double 外,默认按照两次 32 位的操作
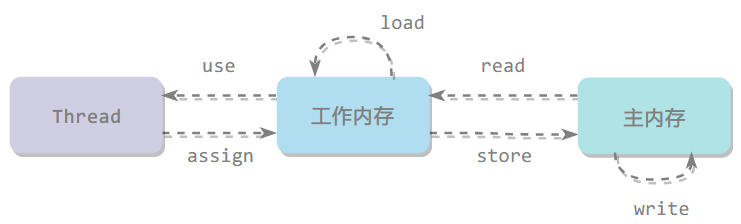
- lock:作用于主内存,将一个变量标识为被一个线程独占状态(对应 monitorenter)
- unclock:作用于主内存,将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定(对应 monitorexit)
- read:作用于主内存,把一个变量的值从主内存传输到工作内存中
- load:作用于工作内存,在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:作用于工作内存,把工作内存中一个变量的值传递给执行引擎,每当遇到一个使用到变量的操作时都要使用该指令
- assign:作用于工作内存,把从执行引擎接收到的一个值赋给工作内存的变量
- store:作用于工作内存,把工作内存的一个变量的值传送到主内存中
- write:作用于主内存,在 store 之后执行,把 store 得到的值放入主内存的变量中