
记忆集
记忆集 Remembered Set 在新生代中,每个 Region 都有一个 Remembered Set,用来被哪些其他 Region 里的对象引用(谁引用了我就记录谁)
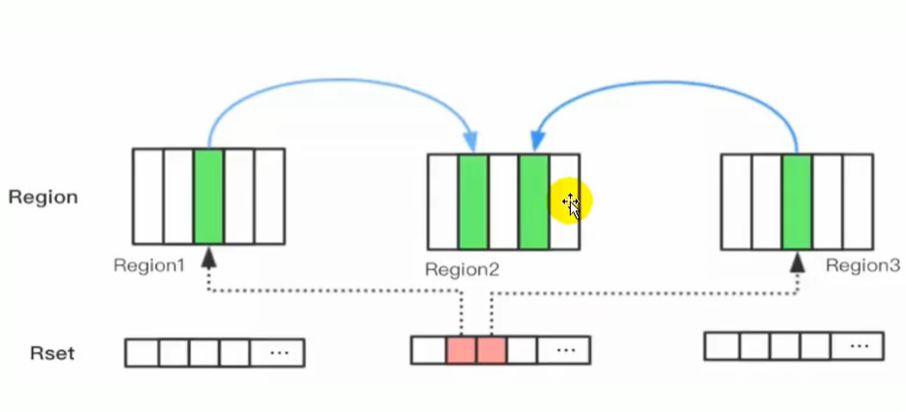
- 程序对 Reference 类型数据写操作时,产生一个 Write Barrier 暂时中断操作,检查该对象和 Reference 类型数据是否在不同的 Region(跨代引用),不同就将相关引用信息记录到 Reference 类型所属的 Region 的 Remembered Set 之中
- 进行内存回收时,在 GC 根节点的枚举范围中加入 Remembered Set 即可保证不对全堆扫描也不会有遗漏
垃圾收集器在新生代中建立了记忆集这样的数据结构,可以理解为它是一个抽象类,具体实现记忆集的三种方式:
- 字长精度
- 对象精度
- 卡精度(卡表)
卡表(Card Table)在老年代中,是一种对记忆集的具体实现,主要定义了记忆集的记录精度、与堆内存的映射关系等,卡表中的每一个元素都对应着一块特定大小的内存块,这个内存块称之为卡页(card page),当存在跨代引用时,会将卡页标记为 dirty,JVM 对于卡页的维护也是通过写屏障的方式
收集集合 CSet 代表每次 GC 暂停时回收的一系列目标分区,在任意一次收集暂停中,CSet 所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。年轻代收集 CSet 只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到 CSet 中
- CSet of Young Collection
- CSet of Mix Collection
跨代引用
什么是跨代引用?
新生代中的对象持有了老年代中的对象的引用 或 老年代中的对象持有了新生代中对象的引用。
跨代引用所带来的问题
当进行一次只局限于新生代区域内的垃圾回收(Minor GC),但是新生代中的对象完全有可能被老年代中的对象所引用。为了找出这个区域中的存活对象,不得不在固定的GC Roots之外,在额外的遍历整个老年代中的对象,来确保可达性分析结果的准确性,反之也是一样,这样就会给内存回收带来很大的负担。
如何解决这个问题
跨代引用假说
存在相互引用关系的两个对象应该是倾向于同生共死的。举个例子,如果新生代对象存在跨代引用,由于老年代对象难以消亡,该引用会使得新生代对象在垃圾收集时同样得以存活,进而在年龄到达阈值后进入老年代中,这时候跨代引用也随之被消除。
解决方案
依据这条假说,只有少量对象才会存在跨代引用的问题。因此没有必要为了少量的跨代引用而去扫描整个老年代,也没有必要浪费空间去专门记录没一个对象是否存在及存在哪些跨代引用,只需要在新生代上建立一个全局的数据结构,这个数据结构将老年代划分为若干个小块,每次都只记录老年代中的哪一块内存存在跨代引用。此后每当发生Minor GC时,只有包含了跨代引用的那一小块内存才会被加入到GC Roots中进行扫描。
上述数据结构就被称之为记忆集,可以简单理解为一种用于记录从非收集区域指向收集区域的指针集合的抽象数据结构。记忆集的记录精度可以分为不同级别,下面展示三种记录精度:
字长精度:每个记录精确到机器字长,该字包含跨代指针
对象精度:每个记录精确到一个对象,该对象的字段中含有跨代指针
卡精度:每个记录精确到一块内存区域,该区域中含有跨代指针
其中,第三种卡精度所指的是一种被称之为卡表的实现方式。
卡表
卡表最简单的形式可以只是一个字节数组。
CARD_TABLE[this address >> 9] = 0;
字节组CARD_TABLE的每一个元素都对应着其标示的内存区域中一块特定大小的内存块,这个内存块被称之为”卡页”。一般来说,卡页大小都是2的N次幂的字节数,从上述代码中可以看出Hotspot中使用的卡页是2的9次幂,即512字节。
一个卡页内存中通常包含不止一个对象,只要卡页内某个对象的字段存在跨代指针,那就将对应卡表数组对应位置上的元素标示为1,称之为Dirty,没有则标示为0,称之为Clean。在垃圾收集时,只需要筛选出卡表中变脏的元素,就能够找到对应卡页内存块中包含的跨代指针,将其加入到GC Roots中一并扫描。

写屏障
卡表元素如何维护?
当有其他分代区域中的对象引用了本区域的对象时,其对应的卡表元素就应该变脏,变脏的时间点原则上应该发生在引用类型字段被赋值的那一刻。
如何在对象赋值的一刻去更新卡表?
假设是解释执行的字节码,虚拟机负责每条字节码指令的执行,有充分的时间介入;但是在编译执行的场景中,经过即时编译后得到的代码已经是纯粹的指令流了,这就必须要找到一个在机器码层面的手段,将维护卡表的动作放到没一个赋值操作中。
在HotSpot虚拟机中是通过写屏障技术来维护卡表的。写屏障可以看做是虚拟机层面上对于“引用类型字段赋值”这个动作的AOP切面,在引用对象赋值时会产生一个环绕式通知,供程序执行额外的动作,也就是说赋值的前后都在写屏障的覆盖范畴内。在赋值前的写屏障叫做写前屏障,在赋值后的写屏障叫做写后屏障。
1 | void oop_field_store(oop* field, oop new_value) { |
写屏障带来的性能问题
应用写屏障后,虚拟机就会为所有的赋值操作生成相应的指令,一旦收集器在写屏障中增加了更新卡表的操作,无论更新的是老年代对新生代对象的引用,每次只要对引用进行了赋值操作,就会判断是否需要更新卡表,从而产生额外的开销,不过这个开销与MinorGC时扫描整个老年代的代价要低的多。