// Java code for stack implementation import java.io.*; import java.util.*; classTest { // Pushing element on the top of the stack staticvoidstack_push(Stack<Integer> stack) { for(int i = 0; i < 5; i++) { stack.push(i); } } // Popping element from the top of the stack staticvoidstack_pop(Stack<Integer> stack) { System.out.println("Pop Operation:"); for(int i = 0; i < 5; i++) { Integer y = (Integer) stack.pop(); System.out.println(y); } } // Displaying element on the top of the stack staticvoidstack_peek(Stack<Integer> stack) { Integer element = (Integer) stack.peek(); System.out.println("Element on stack top: " + element); } // Searching element in the stack staticvoidstack_search(Stack<Integer> stack, int element) { Integer pos = (Integer) stack.search(element); if(pos == -1) System.out.println("Element not found"); else System.out.println("Element is found at position: " + pos); } publicstaticvoidmain(String[] args) { Stack<Integer> stack = new Stack<Integer>(); stack_push(stack); stack_pop(stack); stack_push(stack); stack_peek(stack); stack_search(stack, 2); stack_search(stack, 6); } }
输出 Pop Operation: 4 3 2 1 0 Element on stack top: 4 Element is found at position: 3 Element not found
publicinterfaceQueue<E> extendsCollection<E> { /** * Inserts the specified element into this queue if it is possible to do so * immediately without violating capacity restrictions, returning * {@code true} upon success and throwing an {@code IllegalStateException} * if no space is currently available. * * @param e the element to add * @return {@code true} (as specified by {@link Collection#add}) * @throws IllegalStateException if the element cannot be added at this * time due to capacity restrictions * @throws ClassCastException if the class of the specified element * prevents it from being added to this queue * @throws NullPointerException if the specified element is null and * this queue does not permit null elements * @throws IllegalArgumentException if some property of this element * prevents it from being added to this queue */ booleanadd(E e);
/** * Inserts the specified element into this queue if it is possible to do * so immediately without violating capacity restrictions. * When using a capacity-restricted queue, this method is generally * preferable to {@link #add}, which can fail to insert an element only * by throwing an exception. * * @param e the element to add * @return {@code true} if the element was added to this queue, else * {@code false} * @throws ClassCastException if the class of the specified element * prevents it from being added to this queue * @throws NullPointerException if the specified element is null and * this queue does not permit null elements * @throws IllegalArgumentException if some property of this element * prevents it from being added to this queue */ booleanoffer(E e);
/** * Retrieves and removes the head of this queue. This method differs * from {@link #poll poll} only in that it throws an exception if this * queue is empty. * * @return the head of this queue * @throws NoSuchElementException if this queue is empty */ E remove();
/** * Retrieves and removes the head of this queue, * or returns {@code null} if this queue is empty. * * @return the head of this queue, or {@code null} if this queue is empty */ E poll();
/** * Retrieves, but does not remove, the head of this queue. This method * differs from {@link #peek peek} only in that it throws an exception * if this queue is empty. * * @return the head of this queue * @throws NoSuchElementException if this queue is empty */ E element();
/** * Retrieves, but does not remove, the head of this queue, * or returns {@code null} if this queue is empty. * * @return the head of this queue, or {@code null} if this queue is empty */ E peek(); }
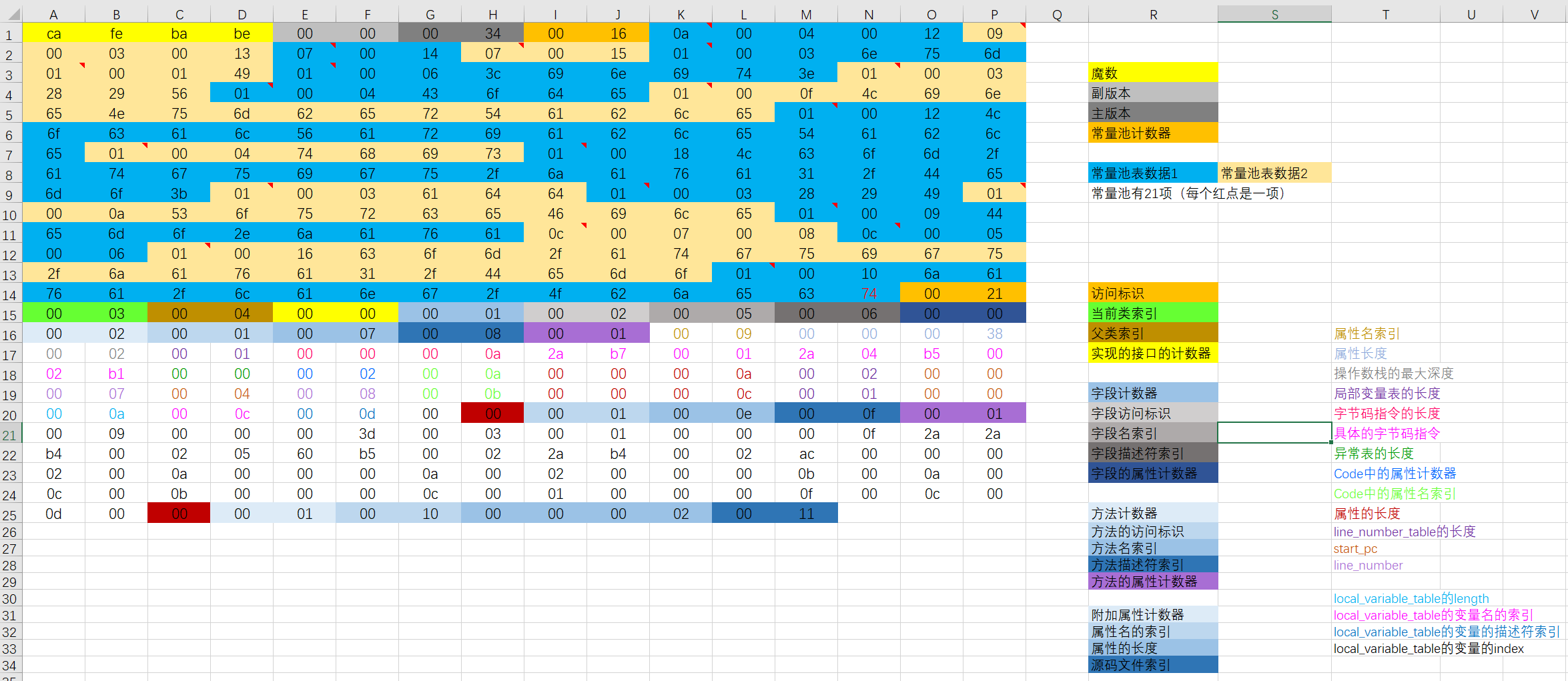
ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }
类型
名称
说明
长度
数量
u4
magic
魔数,识别类文件格式
4个字节
1
u2
minor_version
副版本号(小版本)
2个字节
1
u2
major_version
主版本号(大版本)
2个字节
1
u2
constant_pool_count
常量池计数器
2个字节
1
cp_info
constant_pool
常量池表
n个字节
constant_pool_count-1
u2
access_flags
访问标识
2个字节
1
u2
this_class
类索引
2个字节
1
u2
super_class
父类索引
2个字节
1
u2
interfaces_count
接口计数
2个字节
1
u2
interfaces
接口索引集合
2个字节
interfaces_count
u2
fields_count
字段计数器
2个字节
1
field_info
fields
字段表
n个字节
fields_count
u2
methods_count
方法计数器
2个字节
1
method_info
methods
方法表
n个字节
methods_count
u2
attributes_count
属性计数器
2个字节
1
attribute_info
attributes
属性表
n个字节
attributes_count
Class 文件格式采用一种类似于 C 语言结构体的方式进行数据存储,这种结构中只有两种数据类型:无符号数和表
重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,因为返回值不会包含在特征签名之中,因此 Java 语言里无法仅仅依靠返回值的不同来对一个已有方法进行重载。但在 Class 文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法就可以共存
methods_count(方法计数器):表示 class 文件 methods 表的成员个数,使用两个字节来表示